Railway Oriented Programming
Recognizing error patterns (and the benefits of abstracting them)

I like learning new things, and consider myself a "professional novice." I love learning about software, computational science, optics, and music.
I enjoy solving problems big and small, whether at my day job as a Biomedical Engineer, or on the weekend when I'm learning router port-forwarding and Raspberry Pi computing so my niece and nephews can check in on the latest backyard activity of our newly-webcam-monitored squirrel picnic bench.
Sometimes a problem requires a simple "hack," or 1-off solution specific to the issue at hand. Sometimes, though, there's a characteristic of a solution that keeps recurring. Recognizing those patterns can be powerful, because they can be saved and re-applied to new problems in the future, or in a new domain. Practice noticing the "shape" of a problem-solution pair, then over time you accumulate these patterns in your toolbox for future use.
I just finished re-watching one of my favorite talks by Scott Wlaschin on a topic he coins "Railway Oriented Programming." It's a concise, funny and jargon-light view of patterns in functional programming (that's a lower-case "functional" by the way - while he uses some F# code, the patterns he describes are universal to all languages). He talks specifically about "Straying from the happy path," and how to deal with things that inevitably go wrong with software, without turning your code into a total mess. Per his web page fsharpforfunandprofit.com/rop, here's the blurb for the talk:
Many examples in functional programming assume that you are always on the “happy path”. But to create a robust real world application you must deal with validation, logging, network and service errors, and other annoyances.
So, how do you handle all this in a clean functional way?
This talk will provide a brief introduction to this topic, using a fun and easy-to-understand railway analogy.
In the presentation, Mr. Wlaschin shows how originally-simple, linear, "green field" code gets turned inside out as we attempt to make it robust and "enterprise grade." Our ability to quickly understand and reason about the code plummets as different structures, branches and orchestrations are put in place to combat potential errors. The result is complex code that is very difficult to understand in terms of it's functional intent, and therefore difficult to maintain/modify/improve. This then quickly becomes "read-only" code that accumulates technical debt, and things ultimately grind to a halt. Traditional object-oriented approaches to wrangle some of this complexity - interfaces, proxies, factories, containers - tend to lead to yet more abstraction and still make things initially difficult to understand. It can be a lot of concepts to keep in your head all at once, and can often distract from communicating the intent of the code.
What's remarkable is how in the subsequent presentation he demonstrates that so many of these different challenges in modern software engineering - defensive programming, error checking, exception handling, coordinating async continuations, middleware audits, timeouts/retries - can be mapped to, addressed, and simplified using this simple railway mental model and a few functional-style helpers. The linear code that gets turned into a "Pyramid of Doom" of nested conditionals for catching potential errors, becomes re-linearized by putting the error handling pattern in the functional operators themselves.
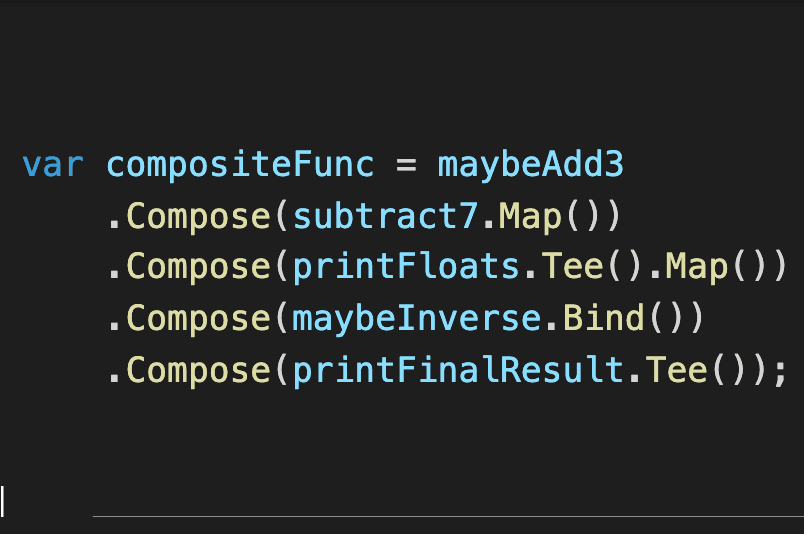
The strategy is basically to adapt existing happy-path functions into two-output "tracks": the "happy path" for the code behaving correctly, and an "error path" for errors, exceptions, etc. Here's a quick example (Choice<T1, T2> is a "Discriminated Union" type...more on that later):
Choice<float, Error> MaybeInverse(float val) => val switch
{
0f => new Error("Inverse!"),
_ => (1 / val)
};
Then, using some simple helper building blocks (shh - they're monads, but I won't tell if you don't), you can stitch these individual components together into a pipeline, which will short circuit or accumulate the undesirable outcomes. He also shows the benefits of mapping errors and exceptions into meaningful domain-model entities that can be carried along with the normal data flow. These help the consumer of the code make more meaningful, reasoned use of the information, versus them having to deal with the multiple "early exit" possibilities that can explode in complexity as the application grows. At the end, he shows the original top-level naïve code next to the new robust error handling code: they're identical. The complexity is managed by the "glue" helper functions underneath, and the meaning/intent of the original code is preserved.
A great benefit of learning Mr. Wlaschin's railway track model is that along the way we also get one of the most accessible and understandable descriptions of functional programming constructs like monads and monoids. It was so clear that without much help, I was able to "follow along at home" and create some C# representations of the concepts and helper functions he describes. In the next post, I'll share some of that work.
Thanks for reading, and talk soon. David
P.S. As an aside, I'm starting this blog because I enjoyed this recent Hanselminutes podcast with Brian Douglas, in which Mr. Douglas mentions platforms like dev.to and hashnode, and encourages devs to avoid common blogging pitfalls and just get to the creating part. Thanks to him for the nudge.